

很早之前就听到一位工程师朋友吐槽,一颗标称几百TOPS的旗舰芯片,把公司自研了大半年的模型放上去跑,实际能调用的算力打了对折。算法团队说是芯片的问题,芯片团队说是算法没优化好,最后谁也没说服谁。
这个场景在今天的智能驾驶行业太常见了。车企发布会上一水的“搭载英伟达Orin/Thor”“算力突破XXXTOPS”,好像芯片算力越高,车就能越聪明。但真正干过这行的人都知道,理论峰值和实际效能之间,隔着一条深不见底的鸿沟。
理想汽车最近干的一件事,让我觉得终于有人想把这笔账算明白了。他们和国创决策智能技术研究所联合发布了一个研究成果——端侧大模型“软硬协同设计定律”。名字听着学术,但捅破的就是那层窗户纸,芯片和算法各跑各的,合在一起效率大打折扣,软硬协同设计定律就是为了解决这一问题。
芯片和算法“不合群”,是行业心照不宣的痛
过去几年,智能驾驶的技术路线变了。从原来的规则驱动,转向以大语言模型为核心的VLA(视觉-语言-行动)系统。简单说,你的车需要在本地跑一个能看懂路况、理解场景、做出决策的“小型GPT”。
问题来了,云端大模型可以拿成千上万张GPU堆,但车载芯片受功耗、散热、成本限制,算力天花板是固定的。更要命的是,芯片团队和算法团队的节奏天生对不上。芯片按摩尔定律走,追求算力线性增长;算法按规模定律走,追求参数指数级扩张。硬凑在一起的结果就是精心设计的模型架构调不动硬件,为了适配硬件做的妥协又满足不了模型智能。
理想在英伟达Orin/Thor平台上被这个问题反复折磨过。他们是最早一批把VLA模型往车上搬的玩家,踩的坑比谁都多。但也正是这种经历,让他们下定决心从根上解决问题。
把“玄学”变成数学,理想是怎么算这笔账的
理想的解法,是把芯片和算法的关系翻译成数学语言。
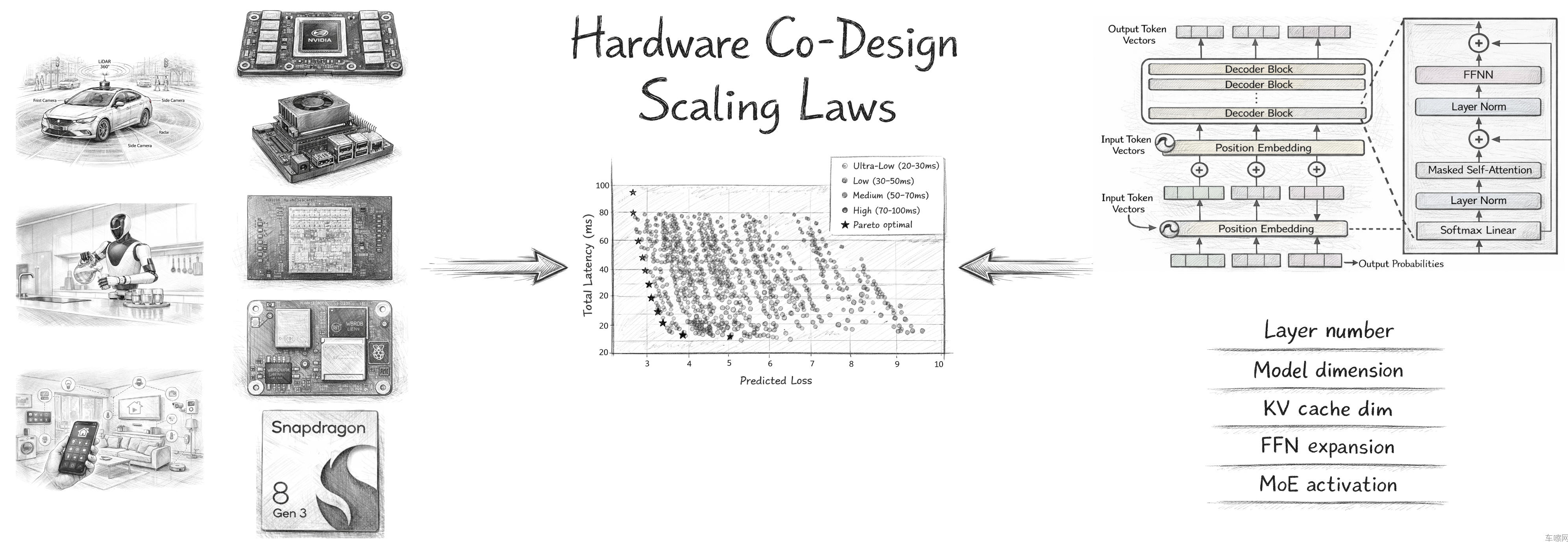
他们先做了一件很笨但很扎实的事:训练了170个不同架构的模型,评估了近2000个候选配置,把Transformer架构的精度表现用多项式拟合出来。以前换一款芯片,算法团队要花几个月试错、调优,现在给定模型参数,不用真跑训练就能预测最后能到什么水平。从“黑箱试错”变成了“白盒预测”。
然后他们把计算机体系结构领域的经典Roofline模型搬了过来,针对车载场景做了改造。KV缓存、MoE路由、注意力机制——这些大模型特有的负载对芯片内存子系统的影响,他们第一次系统性地纳入了建模。简单说,以前只能估算芯片能跑多快,现在能算清楚到底是卡在计算上,还是卡在数据搬运上。
与此同时,理想开发了一个叫PLAS的架构搜索框架。输入芯片的硬件参数(算力、带宽、缓存层次),再输入工程约束(延迟、功耗、内存),这个框架就能自动生成最优的模型架构方案。
这套工具的效果是能算出来的,优化后的模型跟Qwen2.5-0.5B保持完全相同延迟,精度提升了19.42%。同样的硬件,同样的响应速度,跑出来的模型聪明了将近五分之一。
六个发现,每一句都在挑战行业惯例
研究过程中沉淀出的六个技术发现,我觉得比这套公式本身更有意思。它们每一句都在挑战行业延续多年的设计惯例。
第一条,决定车载AI实际表现的,往往不是芯片的峰值算力,而是内存带宽和缓存效率。那些被印在海报最显眼位置的TOPS数字,可能真没大家以为的那么关键。
第二条,稀疏计算将成为车载AI的标配。在车载这种“一次只处理一个请求”的场景下,MoE稀疏架构碾压所有密集架构。未来的芯片必须天生就懂得“挑着算”,只调用必要的神经元,而不是把所有计算单元一起点亮。
第三条,大模型的推理过程分为两个阶段——“理解输入”和“生成答案”,两者对硬件资源的需求完全不同。芯片不能是一条固定的流水线,而需要具备动态调配资源的能力。
第四条,Transformer架构中沿用多年的4倍FFN扩展比,在车载场景下被证明是低效的,芯片内部的计算单元配比需要重新设计。
第五条,INT8量化理论上能快2倍,实际只能快1.3到1.6倍。中间损耗来自精度转换和非线性算子的开销。只有芯片在指令集层面原生支持混合精度计算,才能把这部分效率捡回来。
第六条,没有通用的万能芯片,只有针对特定算法场景深度优化的专属芯片。只有自己最懂自己的算法需要什么,才能造出最高效的芯片。

理想自研智能驾驶芯片马赫100:将理论应用于实践
这套“软硬协同设计定律”首次建立了一套可量化、可预测的软硬协同数学框架,它的第一批工程产物,就是理想自研的智能驾驶芯片“马赫100”。
该芯片采用5nm制程,首搭于即将上市的全新一代理想L9。两颗马赫100组成的双芯片系统,总算力2560TOPS。但说实话,这个数字在这个时代只是个小惊喜。真正让我觉得有意思的,是这颗芯片的诞生方式。
马赫100不是芯片团队拍脑袋定的规格,而是由那套数学公式“算”出来的芯片,针对理想自己的VLA模型做了定向优化。传统芯片的逻辑是“先有房子再让人适应”,马赫100的逻辑是“先问清楚住户需求再动工”。 过去升级芯片更新模型时,研发团队往往需要数月时间进行模型设计和选型。而“软硬协同设计定律”理论上可以将模型设计和选型的周期缩短至一周,大幅提升研发效率。
这套理论诞生的背后,是理想近8年累计近500亿元的研发投入。截至2025年11月,理想围绕BEV、端到端、VLA、世界模型等方向,累计发表近50篇论文,被引用超过2500次,其中32篇登上顶会。此外,理想还将辅助驾驶部分代码和数据集在Github开源,获得了超过3200名开发者的收藏或调用。
写这篇文章的时候,我一直在想一个问题:过去这些年,行业评判芯片好不好,看的是TOPS算力、看制程、看参数规格。这些规则是谁定的?是芯片厂商。车企只能在别人制定的规则里玩。
现在有人开始重新定义规则了。理想这套“软硬协同设计定律”,本质上是在说,真正决定车聪明不聪明的,不是堆了多少算力,而是每一分算力被用到了哪里。
从这个角度看,马赫100的意义可能不只是理想自研的首颗智能驾驶芯片,它释放了一种可能性,当车企开始深度理解自己的算法需要什么样的芯片,当芯片开始为算法“量身定制”,智能驾驶的天花板才有可能被真正打开。
这场人工智能时代下关于“效率”的行业竞赛,或许比我们想象的来得更快一些。
来源:理想汽车
另:所有车嚓号作者,禁止在本网发布诋毁、辱骂、散布谣言、有损国家及公司和个人利益的文章或视频,如有涉及法律问题,自行承担,与本网无关。











